 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeONTrust: A Reference Ontology of Trust
Feb 07, 2026Trust has stood out more than ever in the light of recent innovations. Some examples are advances in artificial intelligence that make machines more and more humanlike, and the introduction of decentralized technologies (e.g. blockchains), which creates new forms of (decentralized) trust. These new developments have the potential to improve the provision of products and services, as well as to contribute to individual and collective well-being. However, their adoption depends largely on trust. In order to build trustworthy systems, along with defining laws, regulations and proper governance models for new forms of trust, it is necessary to properly conceptualize trust, so that it can be understood both by humans and machines. This paper is the culmination of a long-term research program of providing a solid ontological foundation on trust, by creating reference conceptual models to support information modeling, automated reasoning, information integration and semantic interoperability tasks. To address this, a Reference Ontology of Trust (ONTrust) was developed, grounded on the Unified Foundational Ontology and specified in OntoUML, which has been applied in several initiatives, to demonstrate, for example, how it can be used for conceptual modeling and enterprise architecture design, for language evaluation and (re)design, for trust management, for requirements engineering, and for trustworthy artificial intelligence (AI) in the context of affective Human-AI teaming. ONTrust formally characterizes the concept of trust and its different types, describes the different factors that can influence trust, as well as explains how risk emerges from trust relations. To illustrate the working of ONTrust, the ontology is applied to model two case studies extracted from the literature.
Knowledge Graphs Evolution and Preservation -- A Technical Report from ISWS 2019
Dec 22, 2020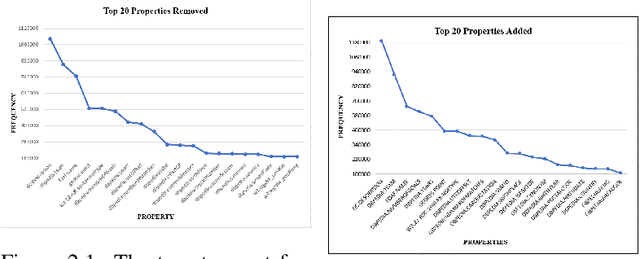
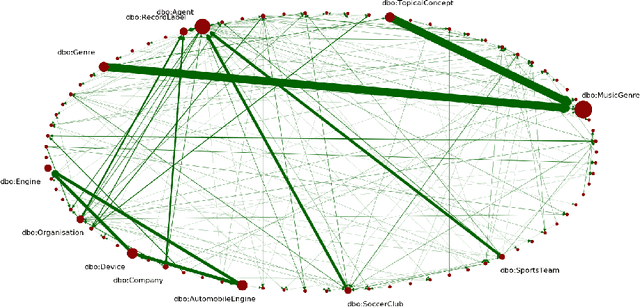

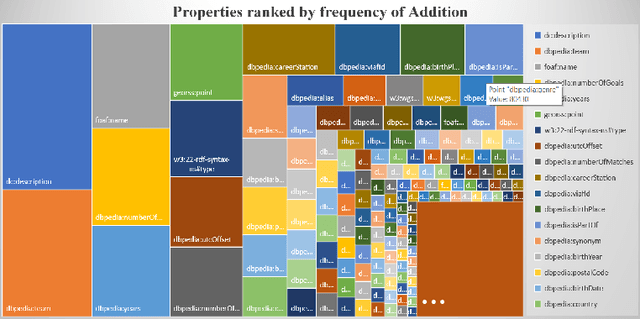
One of the grand challenges discussed during the Dagstuhl Seminar "Knowledge Graphs: New Directions for Knowledge Representation on the Semantic Web" and described in its report is that of a: "Public FAIR Knowledge Graph of Everything: We increasingly see the creation of knowledge graphs that capture information about the entirety of a class of entities. [...] This grand challenge extends this further by asking if we can create a knowledge graph of "everything" ranging from common sense concepts to location based entities. This knowledge graph should be "open to the public" in a FAIR manner democratizing this mass amount of knowledge." Although linked open data (LOD) is one knowledge graph, it is the closest realisation (and probably the only one) to a public FAIR Knowledge Graph (KG) of everything. Surely, LOD provides a unique testbed for experimenting and evaluating research hypotheses on open and FAIR KG. One of the most neglected FAIR issues about KGs is their ongoing evolution and long term preservation. We want to investigate this problem, that is to understand what preserving and supporting the evolution of KGs means and how these problems can be addressed. Clearly, the problem can be approached from different perspectives and may require the development of different approaches, including new theories, ontologies, metrics, strategies, procedures, etc. This document reports a collaborative effort performed by 9 teams of students, each guided by a senior researcher as their mentor, attending the International Semantic Web Research School (ISWS 2019). Each team provides a different perspective to the problem of knowledge graph evolution substantiated by a set of research questions as the main subject of their investigation. In addition, they provide their working definition for KG preservation and evolution.